| La struttura reticolare La struttura dati reticolare e' utilizzata in molti database presenti
su minicomputer e mainframe. Era una delle strutture piu' comuni
per i database prima che i calcolatori diventassero abbastanza potenti
da potersi permettere il modello relazionale. Io ho usato la struttura
reticolare in memoria in molti casi reali con ottimi risultati ma non
ho mai trovato un sistema conveniente per poter implementare questa
struttura in modo riusabile in C, Pascal o C++.
La vecchia cara doppia listaPer descrivere brevemente la struttura dati reticolare cominciamo a
considerare una doppia lista di elementi.
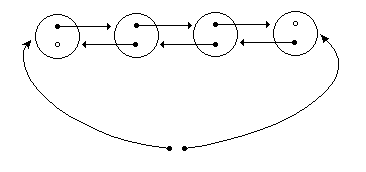
| Una doppia lista
Lo schema di una doppia lista. Ogni nodo ha un puntatore "precedente"
e "successivo" a un altro nodo e sono inoltre presenti puntatori al
primo e all'ultimo nodo della lista.
|
Una prima generalizzazione e' fare in modo che la lista sia a sua
volta un oggetto e mettere in ogni nodo un puntatore alla lista che
lo contiene. Con questa estensione ogni nodo avra' qundi 3 puntatori:
"prev" (precedente), "next" (successivo) e "owner" (proprietario) che
contiene i puntatori "first" (primo) e "last" (ultimo).
Nei diagrammi seguenti non saranno rappresentati i puntatori al
proprietario in quanto la presenza di tutte quelle frecce renderebbe
il diagramma difficile da leggere (e da disegnare ;) ). Poiche' ci sono
piu' proprietari io diro' che ci sono piu' "liste" (una per proprietario)
ma che c'e' una sola "catena" (in altre parole ci sono solo un "prev" e
un "next" per ogni oggetto col significato di "precedente sotto lo stesso
proprietario" e "successivo sotto lo stesso proprietario").
Questa struttura dati permette veloci scansioni sequenziali dirette o
inverse e un tempo costante di inserimento e cancellazione di un nodo
(presupponendo che l'indirizzo del nodo sia noto quando si cancella e
che il punto di inserimento sia noto quando si inserisce).
Un grosso saltoUna generalizzazione piu' interessante e' inserire ogni elemento in
piu' "catene" contemporaneamente. Il prossimo diagramma mostra 5 nodi
che sono inseriti in due diverse catene: la catena "A" e la catena "B".
Ho anche rappresentato 4 differenti proprietari, due per catena.
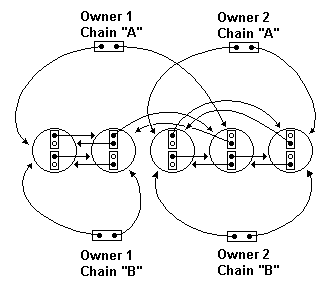
| Una generalizzazione
In questo diagramma sono rappresentati 5 nodi in due diverse catene.
Guardando la prima catena si nota che il primo, secondo e quarto nodo
sono sotto un proprietario mentre il terzo e il quinto sono sotto un
altro proprietario. Nella seconda catena invece la divisione e'
(primo,secondo)/(terzo,quarto,quinto).
|
Disegnare tutti i nodi sta rendendo le figure complesse anche per
casi semplici come quello appena descritto. Da qui in avanti i diagrammi
mostreranno la sola struttura dei nodi, sperando che da questa si
riesca a dedurre facilmente come gli elementi sono collegati fra loro.
In casi reali si trovano nodi che appartengono contemporaneamente anche
a 10 catene distinte.
Un altro grosso saltoLa prossima generalizzazione che voglio introdurre e' il considerare
i proprietari a loro volta come elementi e poter permettere che un
proprietario "possegga" piu' liste distinte. Nella figura seguente ho
rappresentato la struttura di un nodo che sia parte di due catene
distinte e che a sua volta possegga tre liste di nodi.
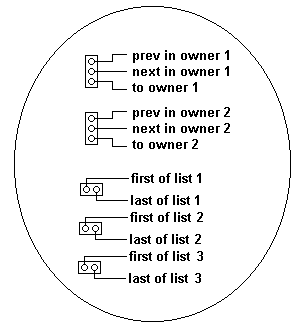
| Un'altra generalizzazione
Struttura di un nodo che e' parte di due catene e che e' proprietario
di tre differenti liste di nodi.
|
Un esempio concreto Visto che le cose si stanno probabilmente facendo confuse per colpa
della mia discutibile descrizione, consideriamo un semplice caso
concreto in cui la struttura reticolare puo' essere impegata. In questo
caso considerero' prodotti, ordini, spedizioni, clienti, prodotti spediti
e prodotti ordinati.
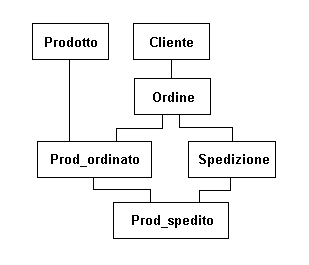
| Un esempio concreto
Un caso concreto in cui la struttura reticolare puo' essere impegata.
I riquadri indicano tipi di elemento, le linee sono le catene.
|
Per leggere lo schema si consideri che i riquadri rappresentano i
diversi tipi di elemento della struttura e che le linee rappresentano
le diverse catene. Una linea che connette un riquadro superiore con uno
inferiore significa che un oggetto del tipo indicato dal riquadro
superiore "possiede" una lista di oggetti del tipo indicato dal riquadro
inferiore.
Nello specifico ho quindi indicato che un cliente possiede una lista
di ordini e che ogni ordine possiede una lista di prodotti ordinati
(un prodotto ordinato indica la quantita' ordinata di un prodotto in
uno specifico ordine). Ho anche immaginato che un ordine possa essere
evaso con piu' spedizioni parziali e quindi ogni ordine possiede una
lista di spedizioni e ogni spedizione indica quali prodotti e in quale
quantita' sono stati spediti.
Considerando ad esempio il tipo di elemento "Prod_ordinato" avro'
bisogno di:
Un puntatore al prodottoUn puntatore al precedente Prod_ordinato relativo allo stesso
ProdottoUn puntatore al successivo Prod_ordinato relativo allo stesso
ProdottoUn puntatore all'OrdineUn puntatore al precedente Prod_ordinato relativo allo stesso
OrdineUn puntatore al successivo Prod_ordinato relativo allo stesso
OrdineUn puntatore al primo Prod_spedito per questo
Prod_ordinatoUn puntatore all'ulimo Prod_spedito per questo
Prod_ordinato Un po' di codice CPer mostrare quanto questa struttura possa diventare noiosa e
ripetitiva da implementare osservate un esempio di funzione "C"
che implementa il distruttore di un elemento di tipo "Prod_ordinato":
typedef struct Prod_ordinato_tag
{
struct Prodotto_tag *prodotto;
struct Prod_ordinato_tag *prev_in_prodotto,*next_in_prodotto;
struct Ordine_tag *ordine;
struct Prod_ordinato_tag *prev_in_ordine,*next_in_ordine;
struct Prod_spedito_tag *first_prod_spedito,*last_prod_spedito;
} Prod_ordinato;
/* ... */
void Delete_prod_ordinato(Prod_ordinato *op)
{
/* Elimina tutti gli elementi di cui sono proprietario */
while (op->first_prod_spedito)
Delete_prod_spedito(op->first_prod_spedito);
/* Fa in modo che l'elemento precedente mi salti (catena 1) */
if (op->prev_in_prodotto)
op->prev_in_prodotto->next_in_prodotto=op->next_in_prodotto;
else
op->prodotto->first_prod_ordinato=op->next_in_prodotto;
/* Fa in modo che l'elemento successivo mi salti (catena 1) */
if (op->next_in_prodotto)
op->next_in_prodotto->prev_in_prodotto=op->prev_in_prodotto;
else
op->prodotto->last_prod_ordinato=op->prev_in_prodotto;
/* Fa in modo che l'elemento precedente mi salti (catena 2) */
if (op->prev_in_ordine)
op->prev_in_ordine->next_in_ordine=op->next_in_ordine;
else
op->ordine->first_prod_ordinato=op->next_in_ordine;
/* Fa in modo che l'elemento successivo mi salti (catena 2) */
if (op->next_in_ordine)
op->next_in_ordine->prev_in_ordine=op->prev_in_ordine;
else
op->ordine->last_prod_ordinato=op->prev_in_ordine;
/* Ok... operazione conclusa, rilascia la memoria del nodo */
free(op);
}
|
|
A prima vista questo codice puo' sembrare complesso ma e' in realta'
semplice e ripetitivo: dopo aver eliminato gli oggetti di cui il nodo
e' proprietario devono essere aggiustati i puntatori precedente e
successivo in modo che questo nodo non faccia piu' parte della catena.
Normalmente si tratta di fare in modo che il successivo del precedente
diventi il successivo di questo nodo e che il precedente del successivo
diventi il precedente di questo nodo ma bisogna gestire come caso
particolare il primo e l'ultimo elemento della lista.
Semplicemente guardando lo schema si potrebbero scrivere senza pensare
troppo qualche centiaio di righe di codice. Stesso codice per tutte le
catene con la sola differenza dei nomi di struttura e di membro.
Provate ad immaginare un caso reale in cui ci possono essere qualche
centinaio di tipi di elemento e qualche migliaio di catene. E' una mole
notevole di codice "C" in cui un programmatore puo' soltanto commettere
errori (pericolosi).
Il problemaIo ho pensato a lungo a una soluzione elegante a questo problema ma
non ho mai trovato nulla di realmente interessante. Quello che faccio e'
scrivere a mano il codice o generarlo automaticamente se devo gestire
strutture con piu' di qualche tipo nodo. In altre parole ho scritto
programmi che leggendo una definizione della struttura possono generare
il codice di gestione puntatori richiesto per le operazioni di
inserimento, cancellazione, cambio proprietario e controllo di
integrita'.
Un esempio di descrizione di struttura per il C++ potrebbe essere:
Prodotto
codice=std::string
descrizione=std::string
prezzo=double
in_magazzino=double
Cliente
codice=std::string
nome=std::string
indirizzo=std::string
cap=std::string
provincia=std::string
Ordine
codice=std::string
data=Date
sconto=double
cliente=Cliente*
Prod_ordinato
prodotto=Prodotto*
ordine=Ordine*
qta=double
sconto=double
Spedizione
ordine=Ordine*
data=Date
nome=std::string
indirizzo=std::string
cap=std::string
provincia=std::string
costo=double
Prod_spedito
prod_ordinato=Prod_odinato*
spedizione=Spedizione*
qta=double
|
|
La descrizione mostrata riguarda un caso semplice in cui non ho tenuto
conto di alcuni particolari importanti. Per esempio quando gli elementi
sono piccoli l'overhead dei puntatori puo' essere ridotto utilizzando
liste semplici e anche il puntatore al proprietario puo' essere rimosso
complicando gli algoritmi di gestione. In qualche database si usa la
tecnica di far puntare l'ultimo nodo al proprietario; con l'aggiunta di
qualche forma di run time type identification questo sistema puo'
portare l'overhead a un puntatore per record per catena (la cancellazione
viene eseguita semplicemente "contrassegnando" l'elemento cancellato
e lo spazio viene recuperato alla prossima scansione della lista).
Inoltre capita abbastanza frequentemente che lo stesso proprietario
possieda piu' di una lista di uno stesso tipo di elemento (nel diagramma
la cosa si indica con piu' linee che collegano gli stessi due rettangoli)
e questo genera alcuni problemi di nomenclatura che non ho mostrato.
STLSTL non e' di grande aiuto in questo caso (o almeno io non so come
potrebbe tornarmi utile). Il problema e' che i contenitori STL prevedono
di essere i *soli* proprietari di un oggetto. Una soluzione che a prima
vista sembra efficace e' utilizzare liste di puntatori (o meglio ancora
liste di handle con reference-counting) ma questa sistema non risolve il
problema in modo corretto.
Per vedere il perche' la cosa non funziona prendiamo il caso concreto
mostrato in precedenza e immaginiamo di avere un membro di tipo
std::list<Prod_ordinato>nella classe Ordine e immaginiamo che una
lista simile sia presente anche nella classe Prodotto: cosa succede
quando vogliamo cancellare un prodotto ? Noi possiamo partire dal
prodotto da cancellare e trovare rapidamente l'elenco degli oggetti
Prod_ordinato associati; siamo pero' obbligati a considerare gli
oggetti Ordine e fare una scansione lineare delle liste che questi
oggetti contengono per poter rimuovere i puntatori agli oggetti
Prod_ordinato che dobbiamo rimuovere.
Immaginate anche un caso reale in cui ci possono essere dieci puntamenti
diversi (puntatori o handle) per raggiungere un determinato oggetto.
Anche se l'accesso all'oggetto tramite uno di questi percorsi sarebbe
veloce noi saremmo costretti a fare nove scansioni lineari per sistemare
le cose in caso di cancellazione di un elemento.
Ho fatto un esempio parlando della cancellazione e qualcuno potrebbe
suggerire di utilizzare una cancellazione "logica". Questa soluzione
non mi convince pero' per due ragioni: la prima e' che non esiste un
buon momento per recuperare lo spazio inutilizzato (a meno di posticipare
la scansione lineare a quando voglio recuperare lo spazio) e inoltre
la cancellazione e' solo un esempio; un'operazione che e' spesso
necessaria e' lo spostare un oggetto da una lista ad un'altra (in altre
parole un'operazione di "cambio proprietario").
Qualche idea brillante ?Mi piacerebbe sentire se qualcuno che sia sopravvissuto a questo
terribile testo ha qualche idea su come rappresentare questa struttura
dati in C o C++ in modo riutilizzabile. Scrivetemi due righe se c'e'
qualcosa che non ho visto. A me sembra che molti contenitori hanno
evitato come STL di implementare la possibilita' importante di avere
accessi bidirezionali multipli ad uno stesso elemento. Per esempio e'
comune avere un albero in cui i nodi sono anche in una list o in una
hash table (non sto pensando ad un albero di hash table, ma a un albero
in cui tutti gli elementi siano in un'unica hash table).
La struttura reticolare e' un caso complesso di struttura dati in cui
esistono diversi percorsi bidirezionali per raggiungere lo stesso dato.
Un caso piu' semplice potrebbe essere un insieme di record che sia
indicizzato da diverse hash table su campi diversi del record.
Io implementerei questa soluzione con una catena di collisioni hash
per ogni campo indicizzato riuscendo quindi ad effettuare le ricerche
con la stessa velocita' che avrei usando una sola hash table ma
riuscendo anche a rimuovere un elemento in un tempo costante (una volta
che l'elemento da eliminare e' stato individuato); non e' questa
un'altra struttura che il C++ avrebbe problemi ad implementare usando
container standard ?
|