| Net data structure The "net" data structure is used in several database systems on minis
and mainframes. It was one of the most common data structure used for
databases when computer were not powerful enough to handle the
relational model. I've been using this data structure in memory in a
lot of real life cases with good results but I never found a convenient
way to put this handling in reusable code with C, Pascal or C++.
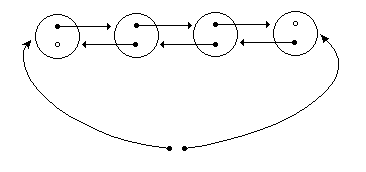
The good old double linked listTo quickly describe the data structure let's start considering a double
linked list of elements.
| Double linked list
A scheme of a double linked list. Every node has a "prev" and "next"
pointer to another node and there are pointers to the first and last
node in the list.
|
A first generalization is making the list itself an object and having
all elements to point to the list object. Using this approach you end
up having all elements with three pointers: "prev", "next" and "owner"
that points to the object that holds the "first" and "last" pointers.
I won't represent pointers to the "owner" object in the following
diagrams because all those arrows would make the pictures difficult to
read (and to draw ;) ). Since there may be more than one "owner" I'll
say that there are more "lists" (one each "owner") but that there is
just one "chain" (i.e. there is just a "prev" and "next" pointer for
every object, meaning "prev under the same owner" and "next under the
same owner").
This data structure allows for quick serial direct and reverse scan and
constant time insertion and deletion of a node (provided element address
is known when deleting and insertion point address is known when
inserting).
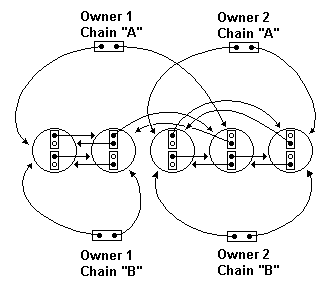
A big jumpAnother more interesting generalization is making every object part
of several different "chains" at the same time. Next diagram shows 5
nodes being part of two different chains: the chain "A" and the
chain "B". I've drawn also 4 different "owners", two per chain.
| A generalization of the concept
In this scheme there are 5 nodes in two different chains. Looking at
the first chain we see that the first, second and fourth node are
under an owner and the third and fifth under another. Looking at the
other chain we see the partition is (first,second)/(third,fourth,fifth).
|
Pictures of instances are becoming confused even for simple cases
like the one depicted. From now on I'll represent just the node
structure hoping that how the elements are joined togheter is easy to
understand looking the scheme. In real life cases it's common to face
objects that are in 10 or more different chains at the same time.
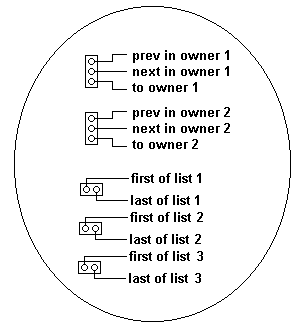
Another big jumpThe next step in generalization I want to make is considering "owners"
as elements themselves and have them to "own" several different lists.
The following picture shows the structure of a single node that is
part of two chains ad the same time and that owns three different lists
of other nodes (with different structure).
| Another generalization
Structure of a node that is part of two distinct chains and that
owns three lists of other nodes.
|
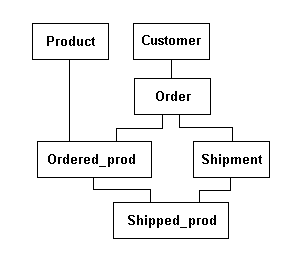
A concrete example As things are getting probably confused because of my poor description
let's consider a concrete simple case in which this data structure can
be employed. This case will consider products, orders, shipments,
customers, shipped products and ordered products.
| A concrete example
A concrete case in which a net data structure can be employed.
Boxes are type of elements, lines are chains.
|
To read the schema consider that boxes represent the differet types
of element in the structure and that lines represent chains. A line
connecting an upper box to a lower box means that every object of the
upper box type is the owner of a list of objects of the lower box type.
So to be specific I depicted that a customer owns a list of orders and
that an order owns a list of ordered products (an ordered product just
tells the quantity ordered of a product in a specific order). I assumed
that an order may be committed in several partial shipments and so every
order owns a list of shipments for that order and every shipment lists
which products and in which quantity have been delivered.
Considering the "Ordered_prod" element type we will need:
A pointer to the ProductA pointer to the previous Ordered_prod element for the same
ProductA pointer to the next Ordered_prod element for the same
ProductA pointer to the OrderA pointer to the previous Ordered_prod element for the same
OrderA pointer to the next Ordered_prod element for the same
OrderA pointer to the first Shipment_prod element for this
Ordered_prod elementA pointer to the last Shipment_prod element for this
Ordered_prod element Some C codeJust to see how things can get annoying and repetitive to implement
look at a "C" example of implementation for the destructor of an
"Ordered_prod" element:
typedef struct Ordered_prod_tag
{
struct Product_tag *product;
struct Ordered_prod_tag *prev_in_product,*next_in_product;
struct Order_tag *order;
struct Ordered_prod_tag *prev_in_order,*next_in_order;
struct Shipped_prod_tag *first_shipped_prod,*last_shipped_prod;
} Ordered_prod;
/* ... */
void Delete_Ordered_prod(Ordered_prod *op)
{
/* Remove all owned elements */
while (op->first_shipped_prod)
Delete_shipped_prod(op->first_shipped_prod);
/* Make who is pointing me from back to skip me (chain 1) */
if (op->prev_in_product)
op->prev_in_product->next_in_product=op->next_in_product;
else
op->product->first_ordered_prod=op->next_in_product;
/* Make who is pointing me from front to skip me (chain 1) */
if (op->next_in_product)
op->next_in_product->prev_in_product=op->prev_in_product;
else
op->product->last_ordered_prod=op->prev_in_product;
/* Make who is pointing me from back to skip me (chain 2) */
if (op->prev_in_order)
op->prev_in_order->next_in_order=op->next_in_order;
else
op->order->first_ordered_prod=op->next_in_order;
/* Make who is pointing me from front to skip me (chain 2) */
if (op->next_in_order)
op->next_in_order->prev_in_order=op->prev_in_order;
else
op->order->last_ordered_prod=op->prev_in_order;
/* Ok... all done, release the memory */
free(op);
}
|
|
This code seems quite complex at a first sight but is indeed really
simple an repetitive: after deleting any owned object the destructor
must fix the chains by making "previous" object to point to "next" ones
and vice versa with special handling if the deleted object is the first
or the last of a list.
Just looking at the schema we can blindly write a few hundred lines of
code in which there's no added value but just pointer fixing. Same code
for all the chains, with just different structure/member names.
Also scale this up to a real case where there may be a few hundred
differen objects and a thousand different chains.
It's some big number of no-think "C" lines in where a programmer can
only make (dangerous) errors.
The problemI've been looking for an elegant solution to this problem for long time
but never found anything interesting. What I've been doing is either
writing all the code by hand or it generating when I faced structures
with more than a few object classes. In other words I wrote programs
that reading a definition of the structure can generate the required
pointer fixing code for insertion, deletion, owner-change and
self-check operations.
An example of this description for C++ could be:
Product
code=std::string
description=std::string
price=double
in_stock=double
Customer
code=std::string
name=std::string
address=std::string
zip=std::string
state=std::string
Order
code=std::string
date=Date
discount=double
customer=Customer*
Ordered_prod
product=Product*
order=Order*
qty=double
discount=double
Shipment
order=Order*
date=Date
name=std::string
address=std::string
zip=std::string
state=std::string
cost=double
Shipment_prod
ordered_prod=Ordered_prod*
shipment=Shipment*
qty=double
|
|
The description shown is for a simple case in which several important
properties have not been considered. For example when dealing with small
objects the pointer overhead may be reduced using one-directional linked
lists and even the pointer to the owner may be removed at expenses of
making algorithms more complex. Some databases makes the last node of a
list pointing to the owner with its "next" pointer; with the addition of
some form of run-time type identification this tecnique makes it
possible an overhead of just a pointer per chain per record (deletion
is often done just "marking" the victim as deleted and having the space
reclaimed at the first scan that encounters a deleted element). Also
it's quite often necessary having the same "owner" to own different lists
of the same element type (in a diagram this is depicted with multiple
lines connecting the same two boxes): this introduces some naming
problem that I've not shown here.
STLSTL isn't helping here (or at least I don't see how to get help from it).
The problem is that STL containers pretend to be the *only* owner of an
object. A tempting solution could be using list of pointers (or even
better lists of reference-counted handles) but this doesn't solve the
problem correctly.
To see why imagine the shown concrete example and imagine the
Order class to have a member of type std::list<Ordered_prod>;
now suppose that such a list is also present as a member in the
Product class: what happens when we want to delete a Product ?
We can start from the Product and quickly find all Ordered_prod related
instances; however we will need a linear scan on Orders and on their
lists to remove all pointers to Ordered_prod we need to delete.
Imagine now a real-life case in which you may have ten different ways
(pointers or handles) to reach the same object. One would be able to
get a quick access using one of the paths, but then it would be
necessary to do nine linear scans to fix up things.
I made an example using a delete request that one could suggest to
replace by a "logical" deletion. However there are two problems with
this solution: first there no good moment when one can reclaim unused
space (unless a linear scan on parents is performed) and second the
delete was just an example; another operation that is quite often needed
is to move and object from one list to another (in other words a
"parent change" operation).
Any good idea ?I would like to hear if anyone that survived this boring text has a
good idea about how to represent this data structure in C or in C++
in a reusable way.
Drop me a line if you see something I missed. My impression is
that many container descriptions avoided as STL the important point
that several data access path may be present for the same element.
For example it's common to have a tree in which the elements are also
in an hash table or a list (i'm not thinking to a tree of hash tables,
but to a tree in which all elements are also in a single hash table).
The net data structure is a complex example of data structure in which
several distinct bidirectional paths are used to get to the same data.
A simpler example could be a set of records searchable using several
distinct hash tables on different fields. I would solve this using
a distinct hash-clash chain for every indexed field thus being able
to search with the same speed as if the element was in a single hash
table but also being able to remove an element in constant time (once
its address is known); isn't this another structure that would be hard to
implement in C++ using standard containers ?
|